Export a docx file in Django application

Exporting file is a commonly used feature that allows users to retrieve their data.
Throughout this series, I will outline various methods for exporting files in a Django application. The exported file formats may include docx, csv, zip, or pdf.
In this initial post of the series, I will introduce the process of exporting a docx file. We will be utilizing a library called python-docx to achieve this.
python-docx
Introduction
python-dox is a Python library for creating and updating Microsoft Word (.docx) files.
Please checkout the official documentation here.
The fundamental concept behind python-docx is to create a document object to which you can add content such as paragraphs, headings, page breaks, tables, pictures and styling options like bold or italic.
Example:
from docx import Document
document = Document()
document.add_paragraph('Lorem ipsum dolor sit amet.')
Installing
To install python-docx, run command:
pip install python-docx
Export view
To enable the download of a docx file through an API, we typically create a view that allows only the GET method.
class ExportDocx(APIView):
def get(self, request, *args, **kwargs):
# create an empty document object
document = Document()
# save document info
buffer = io.BytesIO()
# save your memory stream
document.save(buffer)
# rewind the stream to a file
buffer.seek(0)
# put them to streaming content response
# within docx content_type
response = StreamingHttpResponse(
# use the stream's content
streaming_content=buffer,
content_type='application/vnd.openxmlformats-officedocument.wordprocessingm'
)
response['Content-Disposition'] = 'attachment;filename=Test.docx'
response["Content-Encoding"] = 'UTF-8'
return response
Once we have created an empty document, the next step is to save it and send it to the response.
python-docx provides a document.save() method that acceps a stream instead of a file name.
We can initialize an io.BytesIO() object to store the document information and then send that to the user.
To handle large data and return a response, we use the StreamingHttpResponse function and set the content type to application/vnd.openxmlformats-officedocument.wordprocessingm for docx files.
Build document content
After enable to download an empty docx file, the next step is to begin building the content for the docx. It is recommended to refer to the python-docx documentation for detailed instructions.
To add header text, you can use the .add_heading() method, and to add paragraphs, you can use the .add_paragraph() method.
If you wish to style the text, you can add a run to a paragraph.
As an example, I have created a build_document() method which builds all the content in the document.
def build_document(self):
document = Document()
# add a header
document.add_heading("This is a header")
# add a paragraph
document.add_paragraph("This is a normal style paragraph")
# add a paragraph within an italic text then go on with a break.
paragraph = document.add_paragraph()
run = paragraph.add_run()
run.italic = True
run.add_text("text will have italic style")
run.add_break()
return document
I will then replace the code that creates an empty document in the view with the following:
document = self.build_document()
The current export result is shown below:
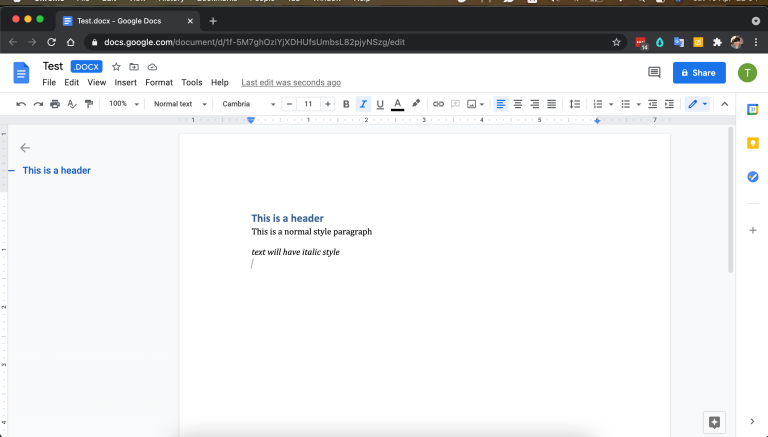
Advance - build html content
Essentially, I can export a docx file with content in it.
To begin with, I simply add the content within a paragraph:
# add paragraph for html content
document.add_paragraph("<p>Nice to see Prep note 2</p><ul><li>Prep note 2 content 1</li><li>Prep note 2 content 2</li></ul>")
However, there was a strange display as following:

I need to find a way to convert HTML content to plain text while preserving basic formatting such as italics, bolding, and bullet points. Here’s an example:
Nice to see Prep note 2
● Prep note 2 content 1
● Prep note 2 content 2
After research around, I discovered a Python built-in library called html.parser - Simple HTML and XHTML parser.
Followed an examle to create a class called DocumentHTMLParser to handle it, as shown below:
class DocumentHTMLParser(HTMLParser):
"""
Document Within HTML Parser
"""
def __init__(self, document):
"""
Override __init__ method
"""
HTMLParser.__init__(self)
self.document = document
self.paragraph = None
self.run = None
def add_paragraph_and_feed(self, html):
"""
Custom method where add paragraph and feed
"""
self.paragraph = self.document.add_paragraph()
self.feed(html)
def handle_starttag(self, tag, attrs):
"""
Override handle_starttag method
"""
self.run = self.paragraph.add_run()
if tag in ["ul"]:
self.run.add_break()
if tag in ["li"]:
self.run.add_text(u' \u2022 ')
def handle_endtag(self, tag):
"""
Override handle_endtag method
"""
if tag in ["li"]:
self.run.add_break()
def handle_data(self, data):
"""Override handle_data method"""
self.run.add_text(data)
The code above involves overriding a function in the HTMLParser class and using the paragraph’s run to customize its style based on the starting tag.
If a tag needs to break on the end, we add a break for it.
I then utilized this custom class in my view to handle the HTML content:
def build_document(self):
"""Build content document"""
document = Document()
doc_html_parser = DocumentHTMLParser(document)
# add a header
document.add_heading("This is a header")
# add a paragraph
document.add_paragraph("This is a normal style paragraph")
# add a paragraph within an italic text then go on with a break.
paragraph = document.add_paragraph()
run = paragraph.add_run()
run.italic = True
run.add_text("text will have italic style")
run.add_break()
# with html content, call method add_paragraph_and_feed tui build content
html_content = "<p>Nice to see Prep note 2</p><ul><li>Prep note 2 content 1</li><li>Prep note 2 content 2</li></ul>"
doc_html_parser.add_paragraph_and_feed(html_content)
Here’s the resulting docx file from the HTML content:

Unit Test
On the backend side, unit testing is a crucial component to protect your application. In my project, each pull request requires a minimum of 80% code coverage through testing, making unit testing a mandatory part of the development process. To aid in writing unit tests, we utilize libraries such as factory_boy and pytest. If you’re unfamiliar with these libraries, you can check out the links provided before proceeding.
In this section, I won’t be covering how to use or write unit tests for a Django application. Instead, I will ensure that the exported docx file has the correct name and type, and that the file contains the expected content and style.
Test content response
I performed some basic checks on the exported file, such as verifying the response status, content type, and file name.
def test_export_docx_general(self):
"""
Ensure general content like
status response, content type, file name exported correctly
"""
response = self.client.get(reverse("export_docx"))
import pdb;pdb.set_trace()
By using import pdb;pdb.set_trace() after making the GET request in the unit test, I am able to inspect the current data.
Here is an example of what it looks like:
<django.http.response.StreamingHttpResponse object at 0x7fc392a61990>
(Pdb) response.status_code
200
(Pdb) response.streaming_content
<map object at 0x7fc3927aadd0>
(Pdb) response.streaming_content.__dir__()
['__getattribute__', '__iter__', '__next__', '__new__', '__reduce__', '__doc__', '__repr__', '__hash__', '__str__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__init__', '__reduce_ex__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
(Pdb) response.get("Content-Type")
'application/vnd.openxmlformats-officedocument.wordprocessingm'
(Pdb) response.get("Content-Disposition")
'attachment;filename=Recipe_Pho_2021-04-15-14-34-09.docx'
As seen in the previous code block, I can continue writing unit tests to check the exported file’s general content, such as the file’s content type, status code, and name.
def test_export_docx_general(self):
"""
Ensure general content like
status response, content type, file name exported correctly
"""
response = self.client.get(reverse("export_docx"))
assert response.status_code == status.HTTP_200_OK
assert response.get("Content-Type") == \
"application/vnd.openxmlformats-officedocument.wordprocessingm"
filename = response.get("Content-Disposition").split("=")[1]
assert filename == "Test.docx"
Please note the response.streaming_content object above which appears as a map object without any data for testing. Initially, I was unsure about how to test the content and style of the document accurately. Despite researching various options, I could not find a suitable solution. Eventually, I came up with a solution for testing the built document myself, which is as follows:
Test document content
I have created a function in the code called build_document to build the document, which is now ready for testing:
def build_document(self):
"""Build content document"""
document = Document()
doc_html_parser = DocumentHTMLParser(document)
# with html content, call method add_paragraph_and_feed tui build content
html_content = "<p>Nice to see Prep note 2</p><ul><li>Prep note 2 content 1</li><li>Prep note 2 content 2</li></ul>"
doc_html_parser.add_paragraph_and_feed(html_content)
My solution was to directly call this function for testing on a mocked view.
Here’s how it appears in the test function:
def test_build_document_for_docx(self):
"""Ensure document built content and style correctly"""
# inline import just for you know where they are
from django.http import HttpRequest
from rest_framework.request import Request as DRFRequest
# mock drf request
request = HttpRequest()
request.method = 'GET'
drf_request = DRFRequest(request)
drf_request.user = self.user
# mock view with request
view = ExportRecipesDocx()
view.request = request
# call function in view directly
document = view.build_document()
import pdb;pdb.set_trace()
Once again, I checked the document profile. As an example, I just have a personal curiosity and love to explore what they are 🥰.
(Pdb) document
<docx.document.Document object at 0x7fd5e65140a0>
(Pdb) document._body.paragraphs
[<docx.text.paragraph.Paragraph object at 0x7fd5e5d5fb50>]
(Pdb) document._body.paragraphs[0].runs
[<docx.text.run.Run object at 0x7fd5e5e419d0>, <docx.text.run.Run object at 0x7fd5e5eba6d0>, <docx.text.run.Run object at 0x7fd5e5eba410>, <docx.text.run.Run object at 0x7fd5e5eba3d0>]
(Pdb) document._body.paragraphs[0].runs[0].text
'Nice to see Prep note 2\n'
(Pdb) document._body.paragraphs[0].runs[0].style.name
'Default Paragraph Font'
(Pdb) document._body.paragraphs[0].runs[0].style.priority
1
(Pdb) document._body.paragraphs[0].runsp[1].text
In my current build_document method, I create a paragraph and add some runs to it, while also inserting breaks where necessary based on the start and end tags of the HTML.
Below is the final version of my unit test for checking the document’s content and styles:
def test_build_document_for_docx(self):
"""Ensure document built content and style correctly"""
# mock request and view initialize like above code
# ...
# call function in view directly
document = view.build_document()
paragraphs = document._body.paragraphs
assert len(paragraphs) == 1
assert paragraphs[0].style.name == "Normal"
assert paragraphs[0].style.priority is None
assert [
'Nice to see Prep note 2',
'\n',
' • Prep note 2 content 1\n',
' • Prep note 2 content 2\n'
] == [item.text for item in paragraphs[0].runs]
assert {None} == {item.italic for item in paragraphs[0].runs}
assert {None} == {item.bold for item in paragraphs[0].runs}
Exporting files in a Django app is a fascinating process, and Python has several libraries that are useful for handling content formats.
Final word
In this article, we discussed a straightforward example of exporting docx files within a Django app.