Các bài viết ngắn về Fundamentals
Các bài viết ngắn về “Fundamentals”:
- Fundamentals
- Giới thiệu về mã nguồn
- Internet hoạt động như thế nào?
- File .gitkeep
- Git commands should know
- Cách đặt tên file
- Viết README thế nào cho chuẩn
- Viết commit message, dễ mà khó
- Authentication là gì?
- Authorization là gì ?
- CS Foundation: algorithms, etc.
- Array
- Tìm kiếm nhị phân (binary search)
- Giải bài toán đồ thị (graph problem) với python
- Học giải quyết vấn đề với Leetcode
- CS50
- Software Principles
- CRUD
- DRY
- Orthogonality
- MVC
- SOLID
Fundamentals
Giới thiệu về mã nguồn
Trong thế giới phần mềm, bạn sẽ hay gặp câu hỏi: “Phần mềm này là loại mã nguồn mở (open source) hay mã nguồn đóng (closed source)?”
Vậy thì mã nguồn là gì? mã nguồn mở hay mã nguồn đóng nghĩa là sao?
Mã nguồn (source code) là phần code của ứng dụng. Ví dụ đơn giản nhất là chương trình hello world, in ra một dòng “Hello Linux!”
print("Hello Linux")
nội dung trên chính là mã nguồn của chương trình viết bằng Python.
Mã nguồn đóng(closed source) là những phần mềm độc quyền với mục đích bảo vệ mã nguồn để tránh cạnh tranh, sao chép, … (Windows, MacOS, …)
Mã nguồn mở(open source) là chương trình có mã nguồn được cung cấp sẵn (Linux, Firefox, Git, …). Open source có thể hiểu là khả năng truy cập vào mã nguồn.
Ngoài ra còn có free source, là những phần mềm được tự do copy hay có thể thay đổi của chương trình, chứ không liên quan đến giá cả.
Open source có rất nhiều lợi ích như được sự đóng góp của cộng đồng, source code tốt hơn và giảm thời gian phát triển phần mềm. Và cũng vì được mở nên sẽ tiếp cận được nhiều người hơn.
Linux thường hay được biết đến là hệ điều hành mã nguồn mở phổ biến. Tuy nhiên thực tế Linux chỉ là một phần mềm nhân (kernel). Mời bạn đọc thêm về các loại mã nguồn và giới thiệu về Linux ở đây.
Internet hoạt động như thế nào?
Bạn sử dụng internet 🌍 mỗi ngày, để làm việc , để học tập online 👩💻, xem phim 👀, nghe nhạc 🎧 và ngay cả lúc đang đọc bài post này ✅.
🤔 Vậy Internet thực sự hoạt động như thế nào?
Vì sao bạn cá mập 🦈 đâu đó ngoài biển khơi lại có thể bị đổ thừa là làm ảnh hưởng đến tốc độ truyền 😹 ?
👉 Giới thiệu đến bạn một video animation cực dễ hiểu về cách internet hoạt động.
Bạn sẽ tham gia vào chuyến phiêu lưu ✈️ của thông tin chính là các dữ liệu 📀 ở dạng bit (1010) từ máy chủ 💾 đến các thiết bị cuối của người dùng 📲.
✅Trong đây bạn sẽ được hiểu thêm về một vài khái niệm như:
- trung tâm dữ liệu (data center), vệ tinh (satellite), cáp quan (fiber cable)
- SSD (solid state device), máy chủ (server)
- địa chỉ IP (IP address), tên miền(domain name)
- DNS server, protocols (HTTP/HTTPS, TCP/IP, RTP)
Mời bạn xem video dưới đây.
.gitkeep
File .gitkeep thường được biết đến như là cách để có thể commit một thư mục trống lên trong quá trình thiết kế cấu trúc thư mục cho dự án của bạn.
Ví dụ cấu trúc một website đơn giản:
src/
|-- assets/
|-- images/
|-- styles/
|-- main.css
index.html
README.md
Nếu không có .gitkeep trong thư mục “images” thì mình không thể commit cả hai thư mục “assets” và “images” lên repo được, kết quả là không giữ được cấu trúc thư mục như trên(hình 1)
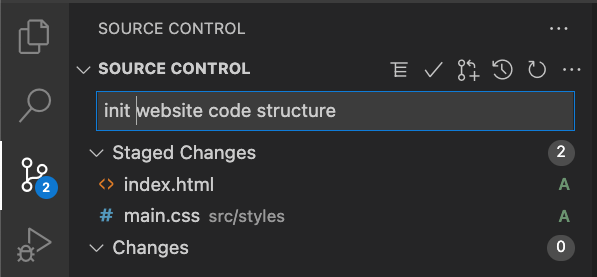
Và đây là kết quả khi đặt .gitkeep trong thư mục “images”, cấu trúc thư mục sẽ được đảm bảo(hình 2)
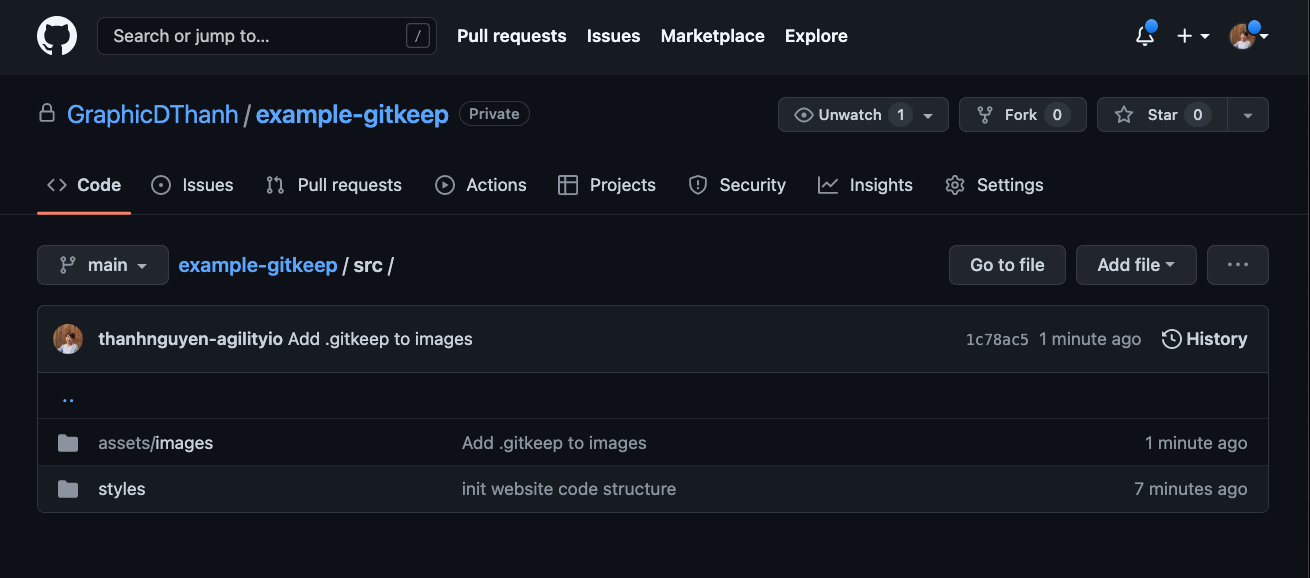
Câu hỏi đặt ra là: tại sao lại là .gitkeep? Có thể dùng file khác thay thế được không?
Trả lời: CÓ thể dùng file khác thay thế! Ví dụ: text.txt hay thậm chí là .gitignore
Tuy nhiên vì mục đích của file này là giữ cho một thư mục có thể trống, theo nghĩa đen của nó, nên theo cách làm tiêu chuẩn sẽ là một file có đủ ý nghĩa trên:
– .gitkeep là file ẩn
– .gitkeep mang ý nghĩa đúng với vai trò của nó
Hi vọng bạn sẽ nhớ đến .gitkeep khi cần commit thư mục trống và hiểu thêm vì sao lại dùng bạn ấy nhé! Cơ mà nói chứ bạn sẽ ít xài lắm, vì thư mục có khi nào trống đâu haha.
Git commands should know
Git sẽ đi cùng bạn suốt thời gian làm dev, vì cứ hễ code là phải commit lên repository của github, gitlab cá nhân hay của dự án, công ty.
Làm chủ Git CLI với 30 câu lệnh mà lập trình viên nên biết với bài viết ở link.
Mình sẽ tóm tắt một số câu lệnh hay sử dụng và quan trọng theo cách mình nhìn nhé.
– Setup usernane và email với “git config”. Câu lệnh này quan trọng khi bạn có nhiều repository khác nhau cần commit với tên và email khác nhau, ví dụ như repo cá nhân và công ty, dự án.
– Clone một dự án về với “git clone”, chuyển branch với “git checkout
– Tạo branch mới với “git branch”, tạo mới và checkout qua luôn với “git checkout -b
– Xem các branch với “git branch”, xem cả cho remote thì thêm option “-a”
– Kiểm tra code changes với “git status”
– Thêm file thay đổi lên staged với “git add”
– Commit một dòng với “git commit -m
– View commit history với “git log”, thêm option -3 sẽ xem 3 commits gần nhất, thêm -p sẽ xem thay đổi trên commit. Xem log đẹp dạng graph thì sử dụng “git log –graph –oneline –decorator”
– Xem một commit với “git show
– Bỏ thay đổi của file chưa lên staged với “git checkout”, nếu lên staged rồi thì dùng “git reset”
– Rollback commit gần nhất với “git revert”
– Xoá branch đã merge với “git branch -d”, nếu có lỗi tức là branch này chưa được merge vào main branch, lúc nãy vẫn muốn xoá cần dùng option “-D”
– Xoá branch ở remote với “git push origin –delete
– Merge hai branch với “git merge”, nếu cần commit merge thì thêm option “–no-ff”
Cách đặt tên file
Bạn đặt tên một file như thế nào?
Ví dụ bạn có một tấm ảnh, bạn sẽ đặt nó tên gì? có thể là “image 1.png” hay “2022-07-12_img1_a-beautiful-dog.png”
Việc đặt tên tưởng chừng rất đơn giản, vì nó dễ làm thật, nhưng nó lại là một trong những thử thách lớn nhất của người dùng thiết bị nói chung, hay một lập trình viên nói riêng. Và cũng đã có rất nhiều thảo luận xoay quanh vấn đề này, kèm theo đó là sự ám ảnh nhẹ với cái tên “naming convention”
Việc đặt tên là quan trọng, vì nó sẽ sử dụng để nhận dạng, tìm kiếm, phân loại, … file này giữa hàng ngàn, hàng triệu file khác.
Có 3 nguyên tắc chính khi đặt tên file: machine readable: máy có thể đọc được human readable: người có thể đọc được plays well with default ordering: cái tên hoạt động tốt với những cách phân loại mặc định(phân loại theo ngày tháng, theo nhóm, …)
Giới thiệu đến bạn chi tiết và ví dụ về ba nguyên tắc trên ở link này. Chúc bạn hiểu thêm về cách đặt tên sao cho chuyên nghiệp, dễ tìm kiếm và dễ phân tích dữ liệu nhé.
Viết README thế nào cho chuẩn
README là tập tin đầu tiên được đọc trong dự án phần mềm, chứa các nội dung quan trọng nhất của dự án như mục đích của dự án, các tính năng tính, các công nghệ được áp dụng, …
Để viết một file README cho chuẩn, gợi ý đến bạn 7 vấn đề mà bạn nên quan tâm:
-
Viết một đoạn ngắn giới thiệu và mục đích của dự án
-
Sắp xếp các nội dung sao cho dễ truy cập (mục lục, phân nội dung theo từng phần, link liên kết, …)
-
Thông tin chung của dự án bổ sung thêm thông tin sau đoạn ngắn giới thiệu ở trên (dự án giải quyết vấn đề gì, dùng kỹ thuật gì: framework, database, …)
-
Hướng dẫn người dùng chạy dự án lên (các phần mềm tiên quyết, cách tải và chạy dự án)
-
Hướng dẫn cách kiểm thử (run tests) nếu có
-
Mô tả về các bugs, vấn đề của dự án đã biết (know issues)
-
Cung cấp các môi trường đã deploy để người dùng trải nghiệm (staging, prod environment)
-
Thường xuyên update README để cập nhật thông tin mới nhất
-
Cuối cùng, một điểm mình hay thấy là “Nhớ đóng vai người dùng để chạy dự án theo cách bạn đã hướng dẫn, và đảm bảo những gì bạn hướng dẫn là chính xác”.
(Ref)
Viết commit message, dễ mà khó
A commit message shows whether a developer is a good collaborator
Một commit message thể hiện người lập trình viên có phải là một người cộng tác tốt hay không
Trong cùng một dự án thì commit message nên thống nhất với nhau về:
– Style: như nội dung bằng tiếng Anh, viết hoa chữ cái đầu tiên, …
– Content: nội dung của message
– Metadata: ticket id, pull request id, …
Luôn luôn “Keep it simple” khi viết một commit message.
Có 7 nguyên tắc giúp bạn viết một commit message tốt hơn:
– Tiêu đề(subject) cách với nội dung một dòng trống
– Tiêu đề tối đa 50 ký tự
– Viết hoa chữ đầu tiên của tiêu đề
– Không viết dấu . cuối tiêu đề
– Sử dụng câu mệnh lệnh khi viết tiêu đề(bắt đầu bằng động từ) Create, Do, Clean, Refactor, Fix, …
– Body nên tối đa 72 ký tự
– Body nên giải thích cho why and how
Mời bạn đọc thêm chi tiết và ví dụ ở bài này.
Authentication là gì?
Là quá trình kiểm tra liệu người dùng có đúng danh tính mà hệ thống có về người ấy hay không. Nếu đúng thì sẽ cho phép người dùng truy cập vào hệ thống. Nếu không đúng thì từ chối truy cập vào hệ thống.
Vậy kiểm tra bằng cách nào?
single factor authentication – cách này hay sử dụng mật khẩu để đăng nhập, và sẽ có rủi ro là nếu bạn sử dụng cùng mật khẩu cho nhiều hệ thống thì nếu hacker hack được mật khẩu của một cái thì tất cả những tài khoản còn lại đều bị rủi ro về bảo mật.
2-factor authentication – cách này an toàn hơn và được sử dụng phổ biến hiện nay vì bên cạnh thông tin đăng nhập (username, password), bạn cần thêm một bên nữa như mã bảo mật gửi về email hay SMS.
multi-factor authentication – cách này còn xịn hơn cách ở trên với sự kết hợp giữa nhiều bên liên quan như thông tin đăng nhập, câu hỏi bảo mật, mã bảo mật (SMS, authenticator app) hay nhận dạng vân tay, khuôn mặt.
Tuỳ vào loại ứng dụng mà chọn cách kiểm tra phù hợp vì không lý gì một ứng dụng giải trí lại yêu cầu quá nhiều thứ từ người dùng như tài khoản ngân hàng.
Authorization là gì ?
Authorization là quá trình kiểm tra xem người dùng có quyền truy cập vào những phần nhất định nào của ứng dụng hay được thực hiện các thao tác cụ thể nào trên ứng dụng.
Bạn cũng có thể nghe về nó với tên “access control” hay “privilege control”. Lưu ý authorization diễn ra sau quá trình authentication, và bao gồm cả cho phép (grant) và từ chối (deny) các quyền. Ví dụ như blog, người dùng sẽ được quyền comment, nhưng chỉ có người dùng đồng thời là tác giả mới có quyền đăng bài.
vậy kiểm tra bằng cách nào?
“role-based access control” – kiểm soát quyền truy cập dựa trên vai trò người dùng trong ứng dụng (viewer, editor, manager, admin, …)
Mỗi role này sẽ có các quyền truy cập nhất định được định nghĩa tuỳ theo cách những loại kỹ thuật bạn dùng.
Ví dụ như trong Django sẽ có sẵn các quyền read, write, edit, view cho từng loại model và bạn có thể kiểm soát quyền truy cập của từng role dựa vào từng loại quyền của model đó.
“claims-based access control” – kiểm soát quyền truy cập dựa trên việc kiểm tra các quyền mà người dùng có.
Ví dụ bạn có một trường owner cho phép xác định chủ sở hữu của đối tượng cụ thể nào đó. Hoặc bạn có một trường account_type cho phép xác định phân loại người dùng.
Bạn đọc thêm ở bài viết này có thêm ví dụ và sơ đồ minh hoạ nhé.
CS Foundation
Array
Mảng (array) là kiểu dữ liệu phổ biến nhất, câu hỏi về mảng thường là quan trọng trong các cuộc phỏng vấn về kỹ thuật dành cho lập trình viên.
Mảng (array) cho phép lưu nhiều phần tử vào một biến duy nhất và truy cập các phần tử trong mảng với index (chỉ mục).
Tuy nhiên, việc thay đổi các phần tử trong mảng diễn ra chậm hơn linked list khi thay đổi các phần tử giữa mảng vì các phần tử còn lại sẽ phải di chuyển để phù hợp với vị trí mới sau khi đã thêm / xóa.
Bên cạnh đó, một số ngôn ngữ yêu cầu kích thước mảng cần khai báo trước và không thể thay đổi sau khi đã khởi tạo. Nếu phần tử được thêm vào vượt quá kích thước mảng thì việc sao chép lại mảng cũ và thêm mảng mới làm tốn thời gian là O(n).
Mời các bạn tìm hiểu thêm về mảng qua các nguồn tài liệu, các kỹ thuật giải toán với kiểu dữ liệu này và các bài toán luyện tập ở [bài blog này][array].
Tìm kiếm nhị phân (binary search)
Tìm kiếm nhị phân (binary search) là một thuật toán tìm kiếm xác định vị trí của một giá trị cần tìm trong một mảng đã được sắp xếp.
Thuật toán sẽ tiến hành so sánh giá trị cần tìm với phần tử đứng giữa của mảng. Nếu hai giá trị không bằng nhau, thì một nửa mảng không chứa giá trị cần tìm sẽ được bỏ qua, và tiếp tục tìm kiếm trên nửa còn lại. Một lần nữa, lấy phần tử ở giữa so sánh với giá trị cần tìm, cứ thế lặp lại cho đến khi tìm thấy giá trị đó. Nếu phép tìm kiếm kết thúc mà vẫn chưa có giá trị cần tìm tức là nó không có trong mảng.
Binary search chạy theo giời gian logarit trong trường hợp tệ nhất, thực hiện O(logn) bước so sánh, với n là số phần tử của mảng. Thuật toán này sẽ nhanh hơn thuật toán tìm kiếm tuyến tính thông thường (lặp qua toàn mảng) với O(n)
Một số vấn đề thường gặp khi giải bài toán binary search:
– Khi nào thì sẽ thoát ra khỏi vòng lặp?
– Làm sao để khởi tạo và cập nhật biên bên trái (left), biên bên phải (right)?
Bài viết sau giới thiệu một bản mẫu tổng quát về cách giải binary search sẽ giúp bạn hình dung về cách giải bài toán này dễ dàng hơn.
Giải bài toán đồ thị (graph problem) với python
Graph là gì?
Graph là một cấu trúc dữ liệu gồm các nút (nodes) hay N và các nhánh (edges) hay E. Loại cấu trúc dữ liệu này thường sử dụng để mô tả khoảng cách giữa các địa điểm hay trong những loại liên kết phức tạp khác.
Node là điểm, thường thể hiện bằng hình tròn, có giá trị (hoặc không). Edge là nhánh, thường thể hiện bằng đường nối giữa hai điểm với nhau, có giá trị (hoặc không)
Giải quyết vấn đề graph
– Duyệt qua graph với Breadth First Search (BFS) hay thuật toán tìm kiếm theo chiều rộng
– Duyệt qua graph với Depth First Search (DFS) hay thuật toán tìm kiếm theo chiều sâu
– Tạo graph với một Adjacency List
– Directed Graph (có một chiều nhất định giữa hai node) và Undirected Graph (giữa hai nút có hai chiều)
Ngoài ra còn có các bài tập cụ thể và được giải với python ở link.
Học giải quyết vấn đề với Leetcode
Bạn muốn học cách giải quyết vấn đề nhưng chưa biết bắt đầu từ đâu? Hay bạn rất thích cấu trúc dữ liệu và thuật toán nhưng chán ngán với mớ sách vở trên trường? Hay bạn cần tìm việc bằng cách luyện giải thuật toán để trả lời các câu hỏi phỏng vấn về kỹ thuật?
Giới thiệu đến bạn một trang mà hầu như ai giải thuật toán hay muốn học về cấu trúc dữ liệu đều sẽ tìm đến, đó là LeetCode.
LeetCode là trang web miễn phí(vài tính năng nâng cao sẽ có phí), nơi bạn có thể luyện đề algorithms cũng như học về các đề tài cấu trúc dữ liệu và thuật toán.
Bạn có thể chọn thử một đề bất kỳ ở mức easy, rồi giải theo ngôn ngữ bạn hay dùng, đó có thể là JS, Python, C++, Go, … Run code rồi submit.
Làm thế sẽ giúp bạn bắt đầu làm quen với các đọc một đề bài, các thông tin liên quan, các gợi ý(nếu có). Khi submit thì LeetCode sẽ chạy phương án code của bạn với bộ test có sẵn(rất nhiều trường hợp) để đảm bảo bạn đưa ra một phương án đủ tốt. Nếu vẫn chưa làm được bạn có thể xem đề bài liên quan đến chủ đề gì rồi tìm chủ để đó để học thêm.
Ngoài ra , trong mục thảo luận của từng bài có rất nhiều các cách giải của những người khác bạn có thể tham khảo để nâng cao dần kỹ năng giải quyết vấn đề. https://leetcode.com/
CS50
Bạn có từng nghe về khoá CS50, một khoá học nền tảng dành cho bất cứ ai muốn bắt đầu với lĩnh vực khoa học máy tính ?
Các chủ đề bao gồm các khái niệm trừu tượng (abstraction), thuật toán (algorithms), cấu trúc dữ liệu (data structures), đóng gói (encapsulation), quản lý mã nguồn (resource management), bảo mật (security), kỹ thuật phần mềm (software engineering), và lập trình web (web programming). Các ngôn ngữ bao gồm C, Python, và SQL, thêm vào đó là HTML, CSS, và JavaScript.
Nội dung theo từng bài học như sau:
- Lecture 0 - Scratch
- Lecture 1 - C
- Lecture 2 - Arrays
- Lecture 3 - Algorithms
- Lecture 4 - Memory
- Lecture 5 - Data Structures
- Lecture 6 - Python
- Lecture 7 - SQL
- Lecture 8 - HTML, CSS, JavaScript
- Lecture 9 - Flask
- Lecture 10 - Emoji
- Cybersecurity
Khoá học 25 giờ này hoàn toàn miễn phí được giảng dạy bởi David J. Malan. Cám ơn freecodecamp cho tài liệu tuyệt vời này!
Lưu ngay vào danh sách todo của bạn để có một bước nền tảng vào ngành khoa học máy tính nha !
Software Principles
CRUD là gì?
Thuật ngữ CRUD, hay CRUD Operation được sử dụng khá phổ biến, đó không phải là một từ mà là viết tắt của Create – Read – Update – Delete, đại diện cho 4 hoạt động chính của một ứng dụng
Ví dụ bạn tạo một app các công việc cần làm (todo list), thì sẽ cần người dùng nhập các công việc cần làm (create), xem được danh sách các công việc (read), thay đổi nội dung công việc (update) hoặc xoá công việc khi không cần làm nữa (delete).
Một ứng dụng CRUD sẽ bao gồm 3 phần chính: server (API) : truyền dữ liệu database : lưu dữ liệu client app (UI) : hiển thị dữ liệu, nơi người dùng nhập dữ liệu
CRUD cũng tương ứng với các phương thức HTTP cụ thể: Create tương ứng với POST Read tương ứng với GET Update tương ứng với PUT/PATCH. PUT là update toàn phần, PATCH là update một phần Delete tương ứng với DELETE
Bạn có thể đọc thêm về các ví dụ ở link sau.
“Don’t Repeat Yourself” hay DRY
Nói cho dễ hiểu hơn, thì khi bạn bắt gặp mình lặp lại một thao tác giống nhau, như việc copy / paste một đoạn code thì đã đến lúc bạn nên tạo cho nó một hàm để sử dụng lại.
Lợi ích dễ thấy của nguyên tắc này là giúp tái sử dụng code, hay “code resuse”.
Nhưng copy / paste code thì code thì có gì sai cơ chứ ?
Thực ra copy / paste code thì cũng không có gì sai trái, nhưng DRY bên cạnh giúp code reuse ra thì còn giúp lập trình viên ẩn đi những đoạn logic quá chi tiết cho từng phần công việc nhỏ giúp giảm tải khối lượng logic lại, nếu cần truy cập thì sẽ tìm đến nơi viết đọc sau.
Vì thế DRY không chỉ là giảm code lặp. Mà bạn đang chia nhỏ một quá trình phức tạp ra thành từng đoạn công việc nhỏ có tên và nhiệm vụ riêng. Từ đó, việc định nghĩa tên hàm, các biến, giá trị trả về, viết document cho hàm cũng trở nên quan trọng, giúp bạn self-document code base của mình.
Don’t repeat yourself hay DRY (2)
Bạn có nghĩ giai đoạn bảo trì (maintenance) là sau khi chương trình được phát hành (release)? Và trong giai đoạn này là các công việc như fix bugs, hay cải thiện các tính năng?
Mình cũng từng nghĩ vậy, nhưng nghĩ vậy là chưa đúng.
Lập trình viên luôn ở trong giai đoạn bảo trì. Bởi sự hiểu của chúng ta thay đổi mỗi ngày, yêu cầu dự án, môi trường, … cũng thường xuyên cập nhật trong khi bạn đang thiết kế, đang code. Vì thế vấn đề về lặp code cũng dễ dàng xảy ra, và đó là vấn đề lớn nhất thường gặp gây khó khăn cho việc bảo trì. Cách tốt nhất để giúp chương trình dễ hiểu và dễ bảo trì, là tuân theo nguyên tắc DRY – Don’t Repeat YourSelf.
Khi đó bạn thay đổi một chỗ, sẽ không cần nhớ phải đổi 2,3 chỗ tương tự. Hay tệ hơn nữa là đổi một chỗ mà những chỗ khác bị sai đi. Và chắc chắn là sẽ có lúc bạn không thể nhớ hết được tất cả các nơi, vậy nên ngay từ đầu hãy viết code theo nguyên tắc DRY. Nhưng vì sao code ngày càng bị lặp?
Có 4 lý do chính:
Lặp vì không thể tránh khỏi
Đôi khi có yêu cầu viết code rõ ràng, lặp nhau vì những mục tiêu cụ thể của dự án (ví dụ như nhiều nền tảng) hay những ngôn ngữ yêu cầu như vậy. Khi đó có một số cách để giúp bạn cải thiện như sử dụng chung các loại tài liệu chung (database chema, pseudo code), comment code, viết document, …
Lặp vì không biết nó bị lặp
Điều này thường xảy ra. Ban đầu, bạn thiết kế chương trình theo yêu cầu A, sau đó chương trình thay đổi yêu cầu sang B và code bạn thiết kế không phù hợp nữa dẫn đến bị lặp. Các quy tắc chuẩn hoá cơ sở dữ liệu, các nguyên tắc trong lập trình hướng đối tượng như SOLID là những cách giúp bạn cải thiện việc thiết kế chương trình.
Lặp vì không cẩn thận, vội vàng
Mọi dự án đều có áp lực về thời gian, và dễ dàng thúc đẩy bạn đi đường nào ngắn nhất để “xong”. Tuy nhiên, sự vội vàng này sẽ mang hậu quả lâu dài. Bạn có thể tiết kiệm thêm 5 phút bây giờ nhưng mất vài tiếng hay thậm chí vài ngày để sửa một con bug (vì không nhớ mình duplicate ra bao nhiêu nơi), hay thậm chí có thể gây dự án thất bại.
Lặp vì có nhiều thành viên và mỗi người code một phần trùng nhau
Làm việc chung nhiều dev dễ dẫn đến trùng lặp. Ví dụ như việc kiểm tra id truyền vào có phải là số hay không, mỗi người làm ở những nơi khác nhau lại thực hiện kiểm tra này khác nhau. Để giảm thiểu tình trạng này, việc review code lẫn nhau trở nên quan trọng trong việc duy trì tính thống nhất của dự án. Các thiết kế chung, các buổi thảo luận sẽ giúp cập nhật, một nơi chung cho những utils dùng lại sẽ có ích.
Vì thế, hãy viết code dễ dàng tái sử dụng. — Lược dịch từ sách “Dragmatic Programmer”
Orthogonality (trực giao)
Orthogonality (trực giao) là khái niệm từ hình học chỉ hai đường thẳng vuông góc. Tức là khi một giá trị chạy dọc theo đường này thì giá trị của đường kia không thay đổi.
Ví dụ như hai trục x, y là trực giao với nhau tại 0. Tức giá trị nào trên x cũng có y là 0 và ngược lại.
Trong máy tính, khái niệm này đại diện cho hai thành phần hay đối tượng độc lập nhau. Tức là nếu thay đổi thành phần này sẽ không làm thay đổi thành phần kia. Orthogonality giúp xây dựng dự án dễ thiết kế, chạy, kiểm thử và mở rộng. Ví dụ việc thay đổi interface như DBMS (database management system) sẽ không ảnh hưởng đến database.
Orthogonality trong thiết kế phần mềm còn là sự kết hợp của hai nguyên tắc: strong cohesion (gắn kết chặt chẽ) và loose coupling (khớp nối lỏng lẻo). Strong cohesion ý chỉ bên trong mỗi thành phần nên được kết nối chặt chẽ. Nếu một thành phần mà có nhiều bộ phận rời rạc thì cũng nên được tách ra thành các thành phần riêng lẻ. Loose coupling ý chỉ giữa các thành phần nên có ít khớp nối. Nếu hai thành phần có kết nối chặt chẽ thì chúng nên gộp lại làm một hoặc nên tách chia theo cách khác để có nhiều thành phần độc lập hơn.
Lợi ích của thiết kế theo hướng trực giao:
Tăng hiệu suất
– thay đổi diễn ra độc lập giữa các thành phần nên chỉ cần thay đổi và kiểm thử cụ thể trên thành phần đó, giảm thời gian lập trình.
– các thành phần độc lập nên dễ tái sử dụng
– kết hợp các thành phần độc lập cũng dễ dàng hơn
Giảm rủi ro
– giảm code liên quan giữa các thành phần
– nếu một thành phần bị lỗi thì sẽ không ảnh hưởng nhiều đến cả hệ thống, dễ debug
– dễ kiểm thử từng thành phần
– hạn chế bị phụ thuộc
Áp dụng tính trực giao trong lập trình: – Giữ mã code tách rời nhau – Tránh dữ liệu toàn cục – Tránh các hàm tương tự nhau
Tập thói quen quan sát và cân nhắc code của bạn, tìm cách để cải thiện cấu trúc và tăng tính trực giao.
Đọc thêm về cặp đôi hủy diệt code xấu DRY và Orthogonality ở bài viết sau
MVC là gì?
Lập trình web ngày càng phát triển, từ ban đầu là các trang web tĩnh chỉ với HTML / CSS rồi phát triển lên trang web động và các hệ thống web ngày càng trở nên đồ sộ với sự làm việc chung của cả ngàn lập trình viên.
Để làm việc với hệ thống ngày càng phức tạp, có nhiều mô hình kiến trúc khác nhau để phân chia code sao cho đỡ phức tạp hơn và dễ dàng làm việc với nhiều người.
Mô hình được sử dụng phổ biến nhất là MVC (Model – View – Controller).
MVC giúp phân chia một ứng dụng lớn thành từng nhóm cụ thể khác nhau với mục đích và nhiệm vụ khác nhau.
Các thành phần:
– Model: Là trung tâm của MVC, model là cấu trúc dữ liệu của ứng dụng, đứng độc lập với giao diện người dùng, chịu trách nhiệm quản lý dữ liệu, xử lý logic.
– View: Là giao diện của ứng dụng
– Controller: Là bộ điều khiển, nhận đầu vào là các yêu cầu và xử lý bằng cách gọi đến View, Model.
Trong mô hình này, Model và View sẽ không tương tác với nhau, chỉ có Controller là nói chuyện với cả Model và View.
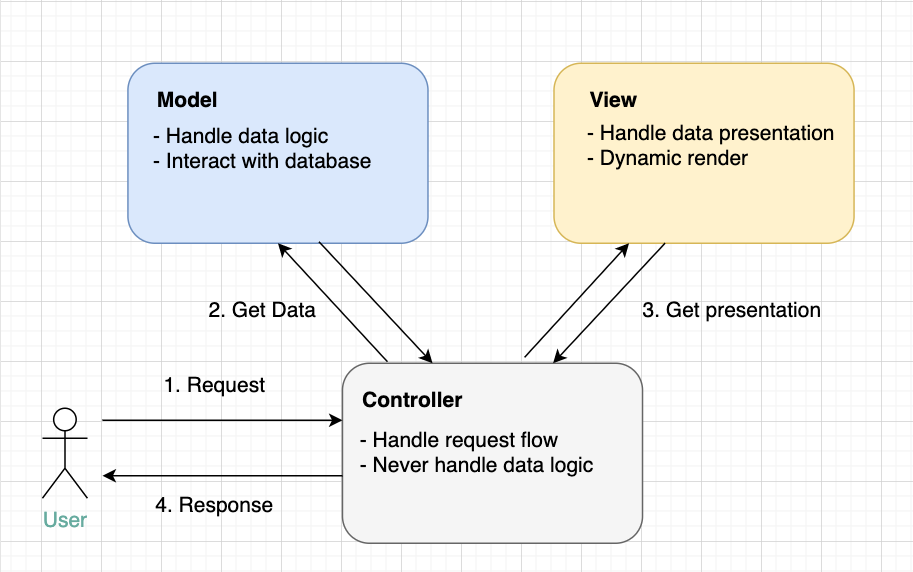
SOLID là gì?
SOLID là nguyên tắc nền tảng trong lập trình hướng đối tượng OOP (Object Oriented Programming) giúp thiết kế hướng đối tượng linh động, dễ hiểu và dễ duy trì
SOLID là viết tắt của 5 chữ cái đầu của: – S: single responsibility principle (SRP) – O: open-closed principle (OCP) – L: Liskov Substitution Principle (LSP) – I: Interface Segregation Principle – D: Dependency Inversion Principle
S: single responsibility principle (SRP) đại diện cho nguyên tắc: “mỗi đối tượng chỉ có một lý do để thay đổi”, điều này có nghĩa là mỗi lớp đối tượng chỉ đại diện cho một loại đối tượng và làm một việc
O: open-closed principle (OCP) đại diện cho nguyên tắc: “các loại thực thể như class, module, hàm, … khuyến khích mở rộng nhưng không khuyến khích chỉnh sửa code có sẵn.
L: Liskov Substitution Principle (LSP) là nguyên tắc chỉ ra lớp con được kế thừa từ lớp cha nên có chung hành vi với lớp cha
I: Interface Segregation Principle chỉ ra rằng nơi sử dụng interface không nên có những loại phương thức có sẵn (từ implement) mà nó không được sử dụng
D: Dependency Inversion Principle chỉ ra hai nguyên tắc chính là:
- Các mô đun cấp cao không nên nạp bất cứ gì từ mô đun cấp thấp mà phụ thuộc nhau qua lớp trừu tượng như interface
- Lớp trừu tượng nên độc lập với các loại thực thi
Đọc khó hiểu thế mà nhìn ví dụ là bạn hiểu hơn ấy, mời bạn đọc bài này mà ngâm cứu thêm hí